支持度と確信度とリフト値
質的データの統計をとるときにはお馴染みの『支持度』『確信度』『リフト値』について。
例えば食べ物の組み合せで
| ご飯 | 納豆 |
| ご飯 | 納豆 |
| ご飯 | 納豆 |
| ご飯 | 焼き魚 |
| ご飯 | 焼き魚 |
というデータがあった時の「ご飯」と「納豆」という組み合わせに着目して、支持度、確信度、リフト値の意味と用途をなるべく分かりやすく解説していきたいと思います。
支持度

例.支持度(ご飯⇒納豆):
(ご飯と納豆の組み合わせが含まれるデータ数)/(全データ数)
これは
「ごはんと納豆という組み合わせは、全体のなかでどれくらいの割合なのか」
を表します。
別名、共起回数。
しかし、これはご飯と納豆の相性(相関関係)について言及できる数値ではありません。
冒頭の表を見てみましょう。
納豆が選ばれている時は必ずご飯が選ばれているのに対して、ご飯は納豆以外の食べ物とも組み合わされています。
また、この支持度はAとBを逆にしても、つまり支持度(ご飯⇒納豆)から支持度(納豆⇒ご飯)と変数を入れ替えても値が変わりません。
この数値は全体として見た時に、その組み合わせがどれくらい起こるかという指標であり、個別の要素について言及するものではないのです。
確信度
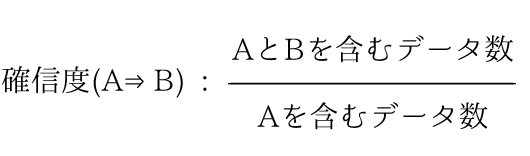
例.確信度(ご飯⇒納豆):
(ご飯と納豆の組み合わせが含まれるデータ数)/(ご飯が含まれるデータ数)
これは
「ご飯を選んだ時に、納豆も一緒に選ばれるのはどれくらいの割合なのか」
を表します。
さっきの支持度と違い、これは個別の要素(この場合はご飯)を基準にして見るものです。当然、確信度(ご飯⇒納豆)を確信度(納豆⇒ご飯)のように変数を入れ替えれば値も変わります。
しかしこれでも相性(相関関係)を見るのには不十分と言わざるを得ません。
例えば、冒頭の表では納豆が選ばれている時にはご飯が必ず選ばれているといっても、ご飯は納豆が選ばれている場合に限らず他の食材の場合でも必ず選ばれています。
これでは単にご飯自体がよく選ばれる食べ物だから納豆との組み合わせも多くなるのか、それとも本当にご飯と納豆の相性がいいのか(相関関係があるのか)が分かりません。
リフト値
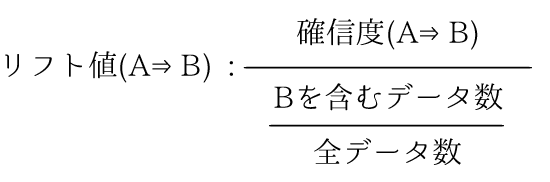
例.リフト値(ご飯⇒納豆):
(ご飯⇒納豆の確信度)/(納豆が含まれるデータ数/全データ数)
確信度(A⇒B)を組み合わせている食材Bが全体の中で占める割合で割ったものですね。
これは
「無条件でBが選ばれる確率よりも、Aが選ばれている条件下でBが選ばれる確率は◯倍高い」
を表します。
例えば、ご飯→納豆のリフト値が仮に5.2だとしたら、
普通に納豆が選ばれる確率よりも、ご飯を選んだ人が納豆を選ぶ確率は5,2倍高い
と言えます。
このリフト値を使って初めて2つの質的データの相関関係をみることができます。
以上、ご参考になれば幸いです。